
View My Project on GitHub
Introduction
In the summer of 2025, I set out to complete the most difficult challenge in AI I could think of. I have always been fascinated by the visual side of AI, so I have always aspired to create my own image generation model. I settled on building DALL·E 2 because I had used DALL·E several times before for other projects and I thought that building my own version from scratch would be a very useful and rewarding experience. Although DALL·E 3 was the newest version available at the time, DALL·E 2 remained the most recent publicly documented and fully published iteration.
DALL·E 2 is a text-to-image generation pipeline developed by OpenAI. Rather than a single model, it consists of several interconnected components that work together to transform a text prompt into a novel image.
Building DALL·E 2 took four months, spanning nearly 10,000 lines of code.
Learn more about how DALL·E 2 works here.
Foundational Learning
This project began when, acting on the advice of a Northeastern professor, I read the 2020 Denoising Diffusion Probabilistic Models (DDPM) paper that introduced diffusion models. Diffusion models are a class of generative AI models that create new data by learning to reverse a noise-adding process. I had little prior experience reading research papers and no experience in generative AI, so reading DDPM was very difficult at first. While working through the paper, I took extremely detailed notes and did not move on until I could reason through every formula and concept from first principles. By the end, I felt like I had truly taken ownership of the paper, and I wanted to learn more about generative AI.
Next, I read Attention Is All You Need, the paper that introduced the Transformer architecture, with the same level of detail. To test my understanding, I implemented the paper for English-to-Spanish translation using low-level PyTorch functions and trained it on my Mac for eight hours. Being able to implement a functional Transformer reinforced the idea that I could build hard things, and I set my sights on implementing and training a simple diffusion model.
However, from the Transformer project, I discovered that I had reached the limits of local pre-training and needed far more compute than my MacBook Pro could provide. I had also always wanted to take a deeper dive into Amazon Web Services, since I viewed AWS as a powerful resource. I completed a two-day interactive AWS course to learn the basics of the main services, which gave me a lot of confidence. Afterward, I mapped out all the services I anticipated using to pre-train a diffusion model and programmatically created interfaces, managers, and unit tests for seven core services: S3, EC2, EBS, VPC, SageMaker, IAM, and Lambda. I made a point of writing extremely well-documented, robust classes suitable for an enterprise-grade application. After spending three weeks writing these AWS classes, I turned my focus back to learning more about DALL·E 2.
I then read DDIM (an improvement over DDPM), U-Net (the model architecture powering diffusion processes), CLIP, BERT, and finally the DALL·E 2 paper.
Implementing DALL·E 2: First Attempt
After teaching myself everything I believed I needed to know about DALL·E 2, I jumped straight into implementation. This process took two weeks of nonstop coding. I started from the lower-level modules (Attention, Residual Blocks, the Upsampler and Downsampler for the U-Net) and worked my way up to the prior (a Transformer-based model that generates text-conditioned image embeddings) and the decoder (a diffusion model guided by the prior’s output).
When I finally had a complete implementation of DALL·E 2, I ran into one error after another when trying to train it (initially on my Mac). To quickly test my pipeline, I attempted to overfit the entire system on a single caption-image pair; if my implementation worked, the decoder would regenerate this single training image. As part of a sophisticated pre-training script, I also ran inference periodically so I could see exactly what my pipeline was producing. However, the model would either output pure Gaussian noise, produce noise heavily saturated in one color channel, or fail with an error. I spent weeks debugging my pipeline and writing tests to diagnose why it wasn’t working. Eventually, I wrote so much extra debugging code that I no longer recognized my original implementation.

I scrapped everything and started over from scratch.
Implementing DALL·E 2: Second Attempt
Learning from my mistakes, I made several key implementation changes that ultimately led to my project’s success. Before writing a single new line of code, I planned every class, function, and even each input and output tensor shape in a PowerPoint document and wrote detailed explanations of how each component fit into the pipeline. This gave me a clear blueprint and ultimately led to a 50% reduction in total implementation time.
Next, instead of building from the bottom up, I implemented the high-level prior and decoder APIs first and worked my way down to the lowest-level modules. This new top-down approach helped me better organize my modules and made me much more confident in the structure of my implementation. Third, just as I wrote extensive unit tests for my AWS classes, I made sure to unit test every component individually. This resulted in much cleaner debugging and better isolation of errors.
These changes produced a far cleaner and leaner implementation — about 9,800 lines of code compared to the original attempt’s 15,000 — and gave me a much better grasp of the DALL·E 2 architecture. Still, it took several more weeks of debugging before I could finally overfit a single training image.

Once both the prior and decoder worked, I felt like I understood DALL·E 2 on a very deep level. While reading and taking notes on the paper gave me a strong conceptual understanding, working through the bugs and dealing with the ambiguity inherent in research papers pushed my understanding to a much more profound level.
Pre-Training DALL·E 2 on AWS: First Attempt
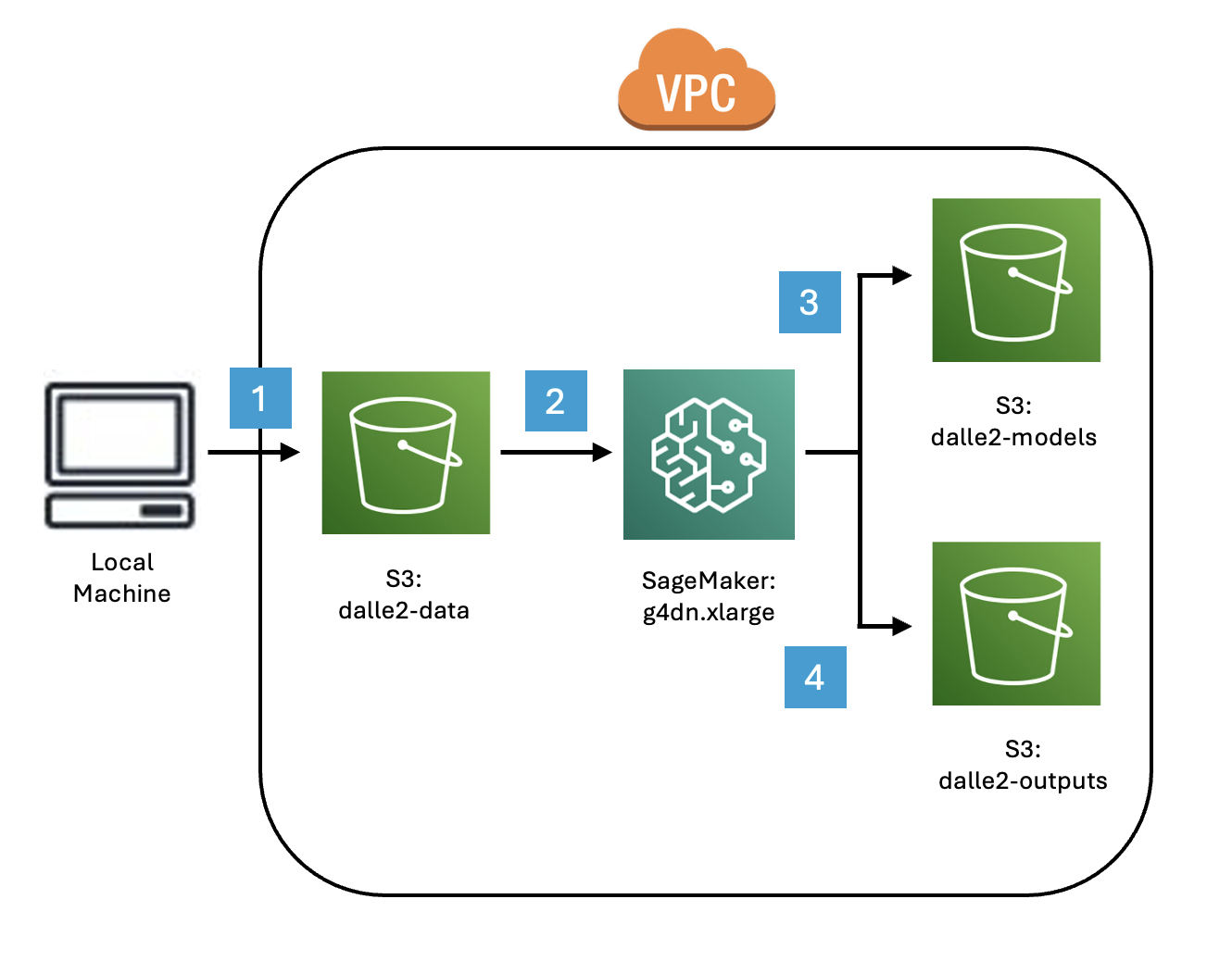
AWS Pre-Training Pipeline
- Upload Dataset to dalle2-data Bucket.
- Cache CLIP Image Embeddings in SageMaker.
- Save Periodic Model Checkpoints to dalle2-models Bucket.
- Save Periodic Decoder Inference Samples to dalle2-outputs Bucket.
Despite perfectly reconstructing a single training image, my pipeline struggled to learn the distribution of my 40,000-image dataset. I ultimately discovered that I needed to add exponential moving average (EMA) weights, a cosine learning rate schedule, and classifier-free guidance. Because the diffusion-powered decoder is far more difficult and expensive to train than the prior, I trained the decoder on a single CUDA-enabled GPU instance on SageMaker while concurrently training the attention-based prior on my MacBook Pro (accelerated by Metal).
The prior converged quickly, but training a 128x128-pixel decoder was a far more difficult task. I eventually ended the decoder training when it produced “good-enough” results.
Finally in August, after setting an ambitious goal in June to build and pre-train my own text-to-image generative pipeline — I had successfully built a proof-of-concept system. The results were far from perfect or commercial quality, but the implementation worked.
Pre-Training DALL·E 2 on AWS: Second Attempt
By October, I felt dissatisfied with my pipeline. I had worked so hard to get my DALL·E 2 pipeline to function that my final results felt like they undersold the amount of effort I put in.
I decided to pre-train the pipeline again, with several major optimizations. First, I used mixed-precision (FP16) weights. Instead of running the CLIP encoder on each image during every training step to obtain ground-truth embeddings, I precomputed all image embeddings for the entire dataset and cached them on the SageMaker instance. This led to much faster training throughput; previously, I pulled the images from an S3 bucket and encoded them at each step.
Just as importantly, instead of training a large 128x128-pixel decoder, I trained a 64x64-pixel decoder (4x fewer pixels) and used an upsampler resolution model to restore the output back to 128x128.
These training optimizations led to a 10x increase in throughput (~5 minutes per epoch instead of ~50 minutes) and 2x faster inference speeds. I also achieved much crisper and more semantically aligned images relative to their input captions.
At this point, I finally had a fully functional DALL·E 2 text-to-image pipeline that produced far better images.
Reflection and Concluding Thoughts
Besides using an open-source CLIP encoder from Hugging Face, I implemented everything 100% myself — from scratch and independently. I did not do this project for school or work credit; I did it purely because I was passionate about generative AI and wanted to challenge myself with the hardest task I thought I could feasibly manage.
Teaching myself, implementing, debugging, and training a complete DALL·E 2 pipeline was undoubtedly the most difficult task I have ever attempted. I brute-forced my way through cascading setbacks at almost every stage of the project. For days at a time, nothing would work, and I had to reassure myself constantly that with enough persistence and mental fortitude, my efforts would eventually lead to a working system.
Going into this project, I had no generative AI experience and had to teach myself everything from scratch. Every setback taught me something new about generative AI, about strong software engineering practices, and about becoming an effective problem-solver. Despite the challenges, I am incredibly proud of the outcome.